|

"Over 66% of enterprises are not confident their organization has a single view of their legacy data, while they recognize that data quality is imperative to business and compliance " NCC |
ArticleDATA WAREHOUSING LESSONS LEARNED: THE IMPACT AND COST OF INFORMATION QUALITY LAPSES
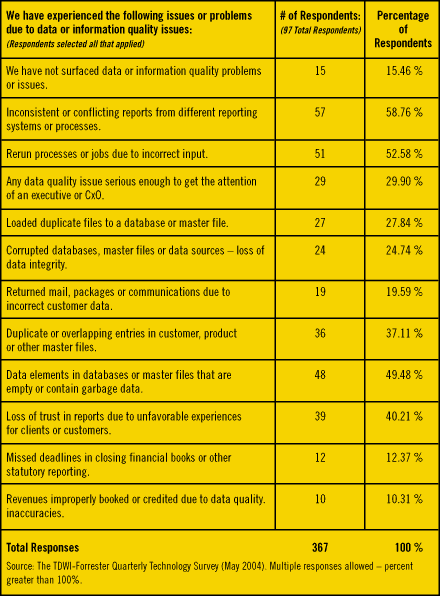
Column published in DM Review Magazine Responses from the TDWI-Forrester Quarterly Technology Survey (May 2004) indicate that information and data quality defects fall into a variety of broad categories (see Figure 1). Respondents identified between three and four of these issues as applying to their own firms, corresponding to the major dimensions of Forrester's definition of information quality. Forrester's working definition of information quality and how to transform dumb data into quality information is: information = objective (data) + usable (data) + trustworthy (data). As attributes of the data are structured according to a defined transformation process along the three high-level dimensions of objectivity, usability and trustworthiness, information quality then improves in precisely those dimensions. We learn about the definition of information quality when IQ breaks down along the three dimensions of objectivity, trustworthiness and usability. Abstracting from and interpreting the data, the top three groups of information quality issues include:
Loss of objective validity. The data in the system does not agree with what is the case in the world. It is not accurate. Mail and packages returned due to incorrect customer contact data are reported by some 20 percent of respondents (Figure 1). Lack of objectivity also shows up as empty, missing or garbage-filled data elements in master files as well as corrupted databases, which are cited by a whopping 50 percent and 25 percent, respectively. Duplicate and overlapping entries in customer and product master files weigh in at 37 percent and are also a clear misfit with objective reality - there is one customer "out there," but the system contains multiple representations, rows or instances. Data integrity is the most important product of the data administration function, and its loss is felt most keenly as the loss of objective validity. Loss of procedural controls. For example, the data in the file is perfectly accurate, but it is loaded into the database twice. This exemplifies the instance where a defined procedure exists, but the practice providing the framework of information quality is incorrectly implemented. The high percentages in the TDWI-Forrester survey due to loading duplicate files and rerun jobs due to incorrect input - some 33 percent and 53 percent, respectively - are really shocking. In such volumes, these kinds of errors, though extremely costly and common, are remediable and can be fixed with modest attention to basic operating methods. Correcting them is low-hanging fruit. Defining, scripting and automating procedures in data center operations will significantly reduce or eliminate clumsy errors in handing off data between systems and within processes. Loss of trust. System users report loss of trust due to unfavorable experiences with the reliability of the data. Inconsistent and conflicting data from different reporting processes is damaging to the credibility of the operations of the entire IT organization. When different reports from different systems express different information about the same set of transactions (data), then the opposite of information is produced. Uncertainty is produced - that is, chaos -- not information. Information Quality Defects are Expensive The impact of these unscheduled system events is significant. The flow of information is disrupted and, therefore, business is interrupted. Though the survey did not capture explicit dollar costs, these are easy to infer because of the precise and granular scope of the issues and answers, including: The cost of inaccurate data. The loss of data integrity and database corruption are show stoppers. They use the time of valuable staffing resources - database administrators - who must perform system archaeology to discover the source of the corruption (or it will keep happening again, which is an even greater cost). In another example, post office penalties for returned packages and misdirected mail are well documented and readily calculated. The 50 percent of respondents who report data elements that are empty or contain garbage data do not use these fields in their system applications. These are perfect examples of digital scrap. They waste disk and processor cycles backing up and re-orging this meaningless data. The cost of uncontrolled procedures. Rerun jobs cost processor (CPU) cycles, the utilization of the disk and network resources, and misuse the time of the IT operations staff needed to disentangle the failed processes and then babysit the recovery effort. The cost of restoring the integrity of a database to which duplicates have been selectively loaded can be prohibitive. In some instances, it is necessary to write a one-shot, custom application to undo the damage. The cost of loss of trust. The loss of trust in reports results in the marching and counter marching of large numbers of people in multiple departments as decisions are delayed, meetings are called and analysis paralysis looms large. In serious cases, the cost is at risk of growing to be coextensive with the value of the entire enterprise as the time and effort of staff, managers and executives reaches the point of thrashing, finger pointing and hand wringing over lost opportunities. Though clients rarely call Forrester to volunteer horror stories about the costs of their really damaging information quality mistakes, we estimate that the difference between an apprentice, entry-level information quality enterprise addressing information quality through heroics and an enterprise with a defined, repeatable, metric-enabled process for continuous information quality improvement is as high as a full order of magnitude. Source: DM Review |
© 2015 IT Dimensions, Inc. All Rights Reserved
If your DQ initiative failed, call us: 1-718-777-3710 | Astoria | New York | USA
|